Hash表
| 附件 | 大小 |
|---|---|
| 1.4 KB |
{kind=link}
在系统实现中,我们多处用到Hash表,如连接的查找和虚拟服务的查找。选择Hash表优先Tree等复杂数据结构的原因是Hash表的插入和删除的复杂度为O(1),而Tree的复杂度为O(log(n))。Hash表的查找复杂度为O(n/m),其中n为Hash表中对象的个数,m为Hash表的桶个数。当对象在Hash表中均匀分布和Hash表的桶个数与对象个数一样多时,Hash表的查找复杂度可以接近O(1)。
因为连接的Hash表要容纳几百万个并发连接,并且连接的Hash表是系统使用最频繁的部分,任何一个报文到达都需要查找连接Hash表,所以如何选择一个高效的连接Hash函数直接影响到系统的性能。连接Hash函数的选择要考虑到两个因素,一个是尽可能地降低Hash表的冲突率,另一个是Hash函数的计算不是很复杂。
一个连接有客户的
和目标服务器的
等元素,其中客户的
#define IP_VS_TAB_BITS CONFIG_IP _VS_TAB_BITS
#define IP_VS_TAB_SIZE (1 >IP_VS_TAB_BITS) ^ port)
& IP_VS_TAB_MASK;
}
为了评价Hash函数的效率,我们从一个运行IPVS的真实站点上取当前连接的样本,它一共含有35652个并发连接。在有64K桶的Hash表中,连接分布如下:
桶的长度(Lj) 该长度桶的个数(Nj)
5 16
4 126
3 980
2 5614
1 20900
通过以下公式算出所有连接查找一次的代价:
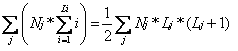
所有连接查找一次的代价为45122,每个连接查找的平均代价为1.266(即45122/35652)。我们对素数乘法Hash函数进行分析,素数乘法Hash函数是通过乘以素数使得Hash键值达到较均匀的分布。
inline unsigned ip_vs_hash_key(unsigned proto, unsigned addr, unsigned port)
{
return ((proto+addr+port)* 2654435761UL) & IP_VS_TAB_MASK;
}
其中,2654435761UL是2到2^32间黄金分割的素数,
2654435761 / 4294967296 = 0.618033987
在有64K桶的Hash表中,素数乘法Hash函数的总查找代价为45287。可见,现在IPVS中使用的移位异或Hash函数还比较高效。
在最新的Linux内核2.4和2.6中,连接的Hash函数是使用Jenkins函数。
参考文献
用户登录
新的论坛主题
在线用户
There are currently 0 users online.
新进会员
- jeanninemartin4054
- feng900628
- silviagrassi8639302
- buddytiegs7720244448
- twylaesmond47523
Comments
Anonymous (没有被验证)
周三, 2006-09-13 03:24
Permalink
这个HASH算法有个问题( http://blog.joycode.com/peon/ )
#define HASH_TAB_MASK_4_1024 0x3FF
inline uint32_t get_hash_index( uint32_t key )
{
return (key* 2654435761ULL) & HASH_TAB_MASK_4_1024;
}
key仅仅只有低位产生作用:
for (i=0; i<0xFF ; i++)
{
ip = (i<<10) + 0x83;
printf("Hello, key %x hash %x\n" , ip, get_hash_index(ip) );
}
结果为
Hello, key 83 hash 193
Hello, key 483 hash 193
Hello, key 883 hash 193
Hello, key c83 hash 193
Hello, key 1083 hash 193
......
Hello, key 3e483 hash 193
Hello, key 3e883 hash 193
Hello, key 3ec83 hash 193
Hello, key 3f083 hash 193
Hello, key 3f483 hash 193
Hello, key 3f883 hash 193
我看到kernel里面是取乘法结果的高位:(hash * 0x9E3779B1) >> (32 - HASH_BITS),这样hash结果比较好
Anonymous (没有被验证)
周三, 2006-09-13 03:27
Permalink
sorry 上面好像贴不全,贴出kernel的算法
(hash * 0x9E3779B1) >> (32 - HASH_BITS)